COMMAND LINE ARGUMENTS
Command line interface (CLI) provides a way for a user to interact with a program running in a text-based shell interpreter
import sys print('Argument List:', sys.argv)
$ python command_line.py arg1 arg2 agr3 Argument List: ['command_line.py', 'arg1', 'arg2', 'agr3']
program name is returned as the argument as well
COLLECTING OBJECT SIZE
getsizeof - Return the size of an object in bytes. The object can be any type of object.
>>> a=[1] >>> b=[1,2] >>> c=[1,2,3] >>> sys.getsizeof(a) 72 >>> sys.getsizeof(b) 80 >>> sys.getsizeof(c) 88
OS MODULE
OS.System lets you run the OS commands from python, for example to clear screen:
on Mac:
import os
os.system('clear')
on Windows:
import os
os.system('cls')
on Mac:
import os
os.system('clear')
on Windows:
import os
os.system('cls')
>>> os.system("pwd") /Users/gulanurmatova/Desktop/python/lecture6 0 >>> os.system("ls") command_line.py cwd.py homework 0
os.getpid()
Return the current process id.
Availability: Unix, Windows.
os.getppid()
Return the parent’s process id.
os.getpid()
Return the current process id.
Availability: Unix, Windows.
os.getppid()
Return the parent’s process id.
$ ps -ef | grep python 501 8599 2572 0 7:10AM ttys000 0:00.00 grep python $ python >>> import os >>> os.getpid() 8601 >>> os.getppid() 2572
os.getlogin()
Return the name of the user logged in on the controlling terminal of the process. For most purposes, it is more useful to use the environment variable LOGNAME to find out who the user is, orpwd.getpwuid(os.getuid())[0] to get the login name of the process’s real user id.
>>> os.getlogin() 'gulanurmatova' >>> os.getppid() 2572
WORKING WITH FILES AND DIRECTORIES

current working directory and directory listing
$ pwd /Users/gulanurmatova/Desktop/python/lecture6 $ ls command_line.py cwd.py
import os print("Current working directory is:{}".format(os.getcwd())) print("Directory Listing:{}".format(os.listdir()))
$ python cwd.py Current working directory is:/Users/gulanurmatova/Desktop/python/lecture6 Directory Listing:['command_line.py', 'cwd.py']
Changing current directory
$ cd homework/ $ ls file.txt
Following 4 code snippets will produce same result
import os os.chdir("homework") print("Current working directory is:{}".format(os.getcwd())) print("Directory Listing:{}".format(os.listdir()))
import os os.chdir("./homework") print("Current working directory is:{}".format(os.getcwd())) print("Directory Listing:{}".format(os.listdir()))
os.path.sep will provide the OS specific path separator character, '/' in case of unix
import os os.chdir(os.getcwd()+os.path.sep+"homework") print("Current working directory is:{}".format(os.getcwd())) print("Directory Listing:{}".format(os.listdir()))
os.path.join uses the system-spcific path join to build path
import os os.chdir(os.path.join(os.getcwd(), "homework")) print("Current working directory is:{}".format(os.getcwd())) print("Directory Listing:{}".format(os.listdir()))
$ python cwd.py Current working directory is:/Users/gulanurmatova/Desktop/python/lecture6/homework Directory Listing:['file.txt']
Example with multiple directories/files join
>>> import os >>> homework_file_path=os.path.join(os.getcwd(), "homework", "file.txt") >>> homework_file_path '/Users/gulanurmatova/Desktop/python/lecture6/homework/file.txt'
check if a path exists:
>>> os.path.exists("homework") True
directory containing the given path:
>>> homework_file_path=os.path.join(os.getcwd(), "homework", "file.txt") >>> os.path.dirname(homework_file_path) '/Users/gulanurmatova/Desktop/python/lecture6/homework'
enclosing directory is returned, note for the path containing directory:
>>> homework_file_path=os.path.join(os.getcwd(), "homework") >>> os.path.dirname(homework_file_path) '/Users/gulanurmatova/Desktop/python/lecture6'
commonprefix provides common path prefix, note it is a plain string comparison and it takes a list as argument

>>> homework_file_path_1=os.path.join(os.getcwd(), "homework", "file.txt") >>> homework_file_path_2=os.path.join(os.getcwd(), "homework", "file_copy.txt") >>> os.path.commonprefix([homework_file_path_1, homework_file_path_2]) '/Users/gulanurmatova/Desktop/python/lecture6/homework/file'
os.path.split - splits the path to passed file/directory from the file/directory
>>> homework_file_path_1=os.path.join(os.getcwd(), "homework", "file.txt") >>> os.path.split(homework_file_path_1) ('/Users/gulanurmatova/Desktop/python/lecture6/homework', 'file.txt')
os.path.splitdrive - splits the path to passed file/directory to drive and the filepath/directorypath, it may look like C:\ or E:\ on windows
for the systems that do not use drives, like Linux, OSX, drive is returned as empty string
>>> os.path.splitdrive(homework_file_path_1) ('', '/Users/gulanurmatova/Desktop/python/lecture6/homework/file.txt')
os.path.splitext - splits the path to passed file/directory to path and extension
>>> homework_file_path_1=os.path.join(os.getcwd(), "homework", "file.txt") >>> homework_file_path_2=os.path.join(os.getcwd(), "homework", "file_copy.txt") >>> os.path.splitext(homework_file_path_1) ('/Users/gulanurmatova/Desktop/python/lecture6/homework/file', '.txt') >>> os.path.splitext(homework_file_path_2) ('/Users/gulanurmatova/Desktop/python/lecture6/homework/file_copy', '.txt')
takes 2(only) parameters and returns True if it is the same path and False otherwise
>>> homework_file_path_1=os.path.join(os.getcwd(), "homework", "file.txt") >>> homework_file_path_2=os.path.join(os.getcwd(), "homework", "file_copy.txt") >>> os.path.samefile(homework_file_path_1, homework_file_path_2) False >>> os.path.samefile(homework_file_path_1, homework_file_path_1) True
another example with same path as different strings
>>> homework_file_path_1=os.path.join(os.getcwd(), "homework") >>> homework_file_path_1 '/Users/gulanurmatova/Desktop/python/lecture6/homework' >>> >>> homework_file_path_2=os.path.join(".", "homework") >>> homework_file_path_2 './homework' >>> os.path.samefile(homework_file_path_1, homework_file_path_2) True
isabs returns True is the path to a file is absolute path and False otherwise
>>> homework_file_path_1=os.path.join(os.getcwd(), "homework") >>> homework_file_path_2=os.path.join(".", "homework") >>> homework_file_path_1 '/Users/gulanurmatova/Desktop/python/lecture6/homework' >>> homework_file_path_2 './homework' >>> os.path.isabs(homework_file_path_1) True >>> os.path.isabs(homework_file_path_2) False
GETTING INFO ABOUT FILES
isfile check wether the passed path a file
>>> homework_file_path_1=os.path.join(os.getcwd(), "homework") >>> homework_file_path_2=os.path.join(os.getcwd(), "homework", "file.txt") >>> os.path.isfile(homework_file_path_1) False >>> os.path.isfile(homework_file_path_2) True
isdir checks wether the passsed path a directory
>>> os.path.isdir(homework_file_path_1) True >>> os.path.isdir(homework_file_path_2) False
Symbolic links, symlink, soft link - a shortcut to a file/directory
$ ln -s /Users/gulanurmatova/Desktop/python/lecture6/homework /Users/gulanurmatova/Desktop/current_lecture

$ ln -s /Users/gulanurmatova/Desktop/python/lecture6/homework/file.txt /Users/gulanurmatova/Desktop/current_file.txt

islink validates if the provided path a symbolic link
>>> homework_file_path_3=os.path.join(os.getcwd(), "..", "..","current_lecture") >>> homework_file_path_1=os.path.join(os.getcwd(), "homework") >>> homework_file_path_2=os.path.join(os.getcwd(), "homework", "file.txt") >>> os.path.islink(homework_file_path_3) True >>> os.path.islink(homework_file_path_1) False
getsize provides byte size of the file or directory
>>> os.path.getsize(homework_file_path_1) 128 >>> os.path.getsize(homework_file_path_2) 0 >>> os.path.getsize(homework_file_path_3) 128
getmtime returns last modified date/time
getatime returns last accessed date/time
>>> os.path.getmtime(homework_file_path_3) 1601547592.0225062 >>> os.path.getatime(homework_file_path_3) 1601547592.1353781

|
Time is returned in Unix epoch format, which is The Unix epoch (or Unix time or POSIX time or Unix timestamp) is the number of seconds that have elapsed since January 1, 1970 (midnight UTC/GMT) https://www.epochconverter.com/ |
CREATING AND CHANGING DIRECTORIES
Following program creates a recursive directory structure with folders test0-test9:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import os print("Current Direcotry:",os.getcwd()) print("Trying to create new directory structure...") for i in range(0,10): directory = "test" + str(i) if(not os.path.exists(directory)): os.mkdir(directory) #create a directory os.chdir(directory) #change directory print("Created ", directory) else: print("Cannot create a directory {0}, already exists", directory) |
on line 8 we are checking if the directory exists, what do you think will happen if the if statement is removed?
Same program once more without line numbers for easy copy-paste
Same program once more without line numbers for easy copy-paste
import os print("Current Direcotry:",os.getcwd()) print("Trying to create new directory structure...") for i in range(0,10): directory = "test" + str(i) if(not os.path.exists(directory)): os.mkdir(directory) #create a directory os.chdir(directory) #change directory print("Created ", directory) else: print("Cannot create a directory {0}, already exists", directory)
READING AND WRITING FILES
Following few code snippets will use this file as source, please download it
| quotes.json |
The file contains quotes in the JSON format, below is a snippet with couple of records from the file
[
{
"text": "Genius is one percent inspiration and ninety-nine percent perspiration.",
"author": "Thomas Edison"
},
{
"text": "You can observe a lot just by watching.",
"author": "Yogi Berra"
},
...
{
"text": "I will prepare and some day my chance will come.",
"author": "Abraham Lincoln"
},
{
"text": "Sometimes the cards we are dealt are not always fair. However you must keep smiling and moving on.",
"author": "Tom Jackson"
}
]
To read the JSON from a file and print:
import json import pprint with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) pprint.pprint(data)
To parse the JSON and print out only the quotes text:
import json with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) for node in data: print(node["text"])
open() returns a file object, and is most commonly used with two arguments: open(filename, mode).
The first argument is a string containing the filename.
The second argument is another string containing a few characters describing the way in which the file will be used. mode can be
'r' when the file will only be read,
'w' for only writing (an existing file with the same name will be erased), and
'a' opens the file for appending; any data written to the file is automatically added to the end.
'r+' opens the file for both reading and writing.
The mode argument is optional; 'r' will be assumed if it’s omitted.
To write just the quotes text to another text file:
import json out = open("just_quotes.txt", "w") with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) for node in data: out.write(node["text"]) out.write("\n") out.close()
Read text file:
with open("just_quotes.txt", "r") as quotes_file: while True: quote = quotes_file.readline() if not quote: break print (quote)
Enumerating through file:
quotes_file = open("just_quotes.txt", "r") for i, quote in enumerate(quotes_file): print ("{}:{}".format(i,quote))
Last two lines of the output:
1641:I will prepare and some day my chance will come. 1642:Sometimes the cards we are dealt are not always fair. However you must keep smiling and moving on.
In class exercise:
Write a program that will create a directory with author's name and put all the quotes belonging to that author into the directory
Replace all spaces in the Author names with underscores
Edge cases:
* Some authors in the JSON are null, replace those with "Unknown"
* There may be special characters in the author names that may not work as filenames
SOLUTION:
Initially let's retrieve the program that loads the JSON from the quotes file
import json with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file)
Now, loop through the author's and print them out (just to make sure we are getting the author's name)
import json with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) for node in data: print(node["author"])
replace the spaces with underscores and print again, to make sure sting replacement is working
If there were no nulls in the author names, this should have worked:
import json with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) for node in data: dir_name = node["author"].replace(" ", "_") print(dir_name)
However, when the author is null, calling replace will blow up, hence we need to handle that:
import json with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) for node in data: corrected_author = node["author"] if node["author"] is not None else "Unknown" dir_name = corrected_author.replace(" ", "_") print(dir_name)
Note: we are using one line if-else statement here which we haven't yet seen in this class, please remember that.
Now the output looks like this:
... Aristotle Napoleon_Hill William_Shakespeare Tony_Robbins Abraham_Lincoln Tom_Jackson
We can now try creating directories:
(I will create one common parent directory, so that if I have to delete the directories the program created, I don't accidentally delete python files)
Parent directory creation and switching the directory:
import json, os with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) for node in data: corrected_author = node["author"] if node["author"] is not None else "Unknown" dir_name = corrected_author.replace(" ", "_") os.mkdir("quotes_output") #parent directory os.chdir("quotes_output") #change directory so that we are inside the parent directory print("Created parent directory ", "quotes_output")
Note: two modules are imported using commas, remember you can have two import statements on different lines or you can list modules using comma on one line
I don't like that I had to repeat the parent directory name in 3 different places explicitly, if I will need to change the name in future, I will have to make sure I don't make a mistake of forgetting to change it everywhere, so I am going to move it to its own variable:
import json, os PARENT_DIR = "quotes_output" with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) for node in data: corrected_author = node["author"] if node["author"] is not None else "Unknown" dir_name = corrected_author.replace(" ", "_") os.mkdir(PARENT_DIR) #parent directory os.chdir(PARENT_DIR) #change directory so that we are inside the parent directory print("Created parent directory ", PARENT_DIR)
Note: Unlike other programming languages, there is no straight forward way to define a constant in Python
If we run the program above twice in a row, we will get an error:
$ python quotes_reader.py Created parent directory quotes_output $ python quotes_reader.py Traceback (most recent call last): File "quotes_reader.py", line 12, in <module> os.mkdir(PARENT_DIR) #parent directory FileExistsError: [Errno 17] File exists: 'quotes_output'
So let's handle that, we will delete the directory if it already exists:
os.rmdir() can be used to delete a directory
import json, os PARENT_DIR = "quotes_output" with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) for node in data: corrected_author = node["author"] if node["author"] is not None else "Unknown" dir_name = corrected_author.replace(" ", "_") #if the parent directory already there, we will delete it if os.path.exists(PARENT_DIR): os.rmdir(PARENT_DIR) os.mkdir(PARENT_DIR) #parent directory os.chdir(PARENT_DIR) #change directory so that we are inside the parent directory print("Created parent directory ", PARENT_DIR)
We will soon run into new problem with that directory, but will move on for now
I think we are ready to start creating those sub-directories with the author names! I'll move the for loop to the bottom because I will need it after the parent directory is created and add the directory creation, this should work:
import json, os PARENT_DIR = "quotes_output" with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) #if the parent directory already there, we will delete it if os.path.exists(PARENT_DIR): os.rmdir(PARENT_DIR) os.mkdir(PARENT_DIR) #parent directory os.chdir(PARENT_DIR) #change directory so that we are inside the parent directory print("Created parent directory ", PARENT_DIR) for node in data: corrected_author = node["author"] if node["author"] is not None else "Unknown" dir_name = corrected_author.replace(" ", "_") os.mkdir(dir_name)
but it doesn't, I get following error:
$ python quotes_reader.py Created parent directory quotes_output Traceback (most recent call last): File "quotes_reader.py", line 19, in <module> os.mkdir(dir_name) FileExistsError: [Errno 17] File exists: 'Yogi_Berra'
It looks like Yogi Berra was too wise and wrote more than one quote, same can happen for other authors, so we need to change the program such that we only create the directory if it doesn't already exist.
import json, os PARENT_DIR = "quotes_output" with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) #if the parent directory already there, we will delete it if os.path.exists(PARENT_DIR): os.rmdir(PARENT_DIR) os.mkdir(PARENT_DIR) #parent directory os.chdir(PARENT_DIR) #change directory so that we are inside the parent directory print("Created parent directory ", PARENT_DIR) for node in data: corrected_author = node["author"] if node["author"] is not None else "Unknown" dir_name = corrected_author.replace(" ", "_") os.mkdir(dir_name) if not os.path.exists(dir_name) else print("{} already exists".format(dir_name))
Now, if I re-run the program, I get a new error, because I cannot remove not empty directory using os.rmdir
$ python quotes_reader.py Traceback (most recent call last): File "quotes_reader.py", line 10, in <module> os.rmdir(PARENT_DIR) OSError: [Errno 66] Directory not empty: 'quotes_output'
We can use shutil.rmtree instead of the or.rmdir to fix that
import json, os import shutil PARENT_DIR = "quotes_output" with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) #if the parent directory already there, we will delete it if os.path.exists(PARENT_DIR): shutil.rmtree(PARENT_DIR)#os.rmdir(PARENT_DIR) os.mkdir(PARENT_DIR) #parent directory os.chdir(PARENT_DIR) #change directory so that we are inside the parent directory print("Created parent directory ", PARENT_DIR) for node in data: corrected_author = node["author"] if node["author"] is not None else "Unknown" dir_name = corrected_author.replace(" ", "_") os.mkdir(dir_name) if not os.path.exists(dir_name) else print("{} already exists".format(dir_name))
Now we can create the quote files in the directories:
import json, os import shutil PARENT_DIR = "quotes_output" with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) #if the parent directory already there, we will delete it if os.path.exists(PARENT_DIR): shutil.rmtree(PARENT_DIR)#os.rmdir(PARENT_DIR) os.mkdir(PARENT_DIR) #parent directory os.chdir(PARENT_DIR) #change directory so that we are inside the parent directory print("Created parent directory ", PARENT_DIR) for node in data: corrected_author = node["author"] if node["author"] is not None else "Unknown" dir_name = corrected_author.replace(" ", "_") os.mkdir(dir_name) if not os.path.exists(dir_name) else print("{} already exists".format(dir_name)) os.chdir(dir_name) # go inside the newly created directory out = open("quote.txt", "w") out.write(node["text"]) out.close() os.chdir("..") # go one level up in the directory tree
This did create the quote files, but when I checked the Yogi Berra quotes, there was only one quote and we know for sure there should be more than one because we got the error before, this happened because the "w" overwrites the file if it already exists, we will change that to "a" and add couple of line feeds to visually separate the quotes
|
You will Need to modify this program below for your homework (Program 2), this is a marker.
|

|
import json, os import shutil PARENT_DIR = "quotes_output" with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) #if the parent directory already there, we will delete it if os.path.exists(PARENT_DIR): shutil.rmtree(PARENT_DIR)#os.rmdir(PARENT_DIR) os.mkdir(PARENT_DIR) #parent directory os.chdir(PARENT_DIR) #change directory so that we are inside the parent directory print("Created parent directory ", PARENT_DIR) for node in data: corrected_author = node["author"] if node["author"] is not None else "Unknown" dir_name = corrected_author.replace(" ", "_") os.mkdir(dir_name) if not os.path.exists(dir_name) else print("{} already exists".format(dir_name)) os.chdir(dir_name) # go inside the newly created directory out = open("quote.txt", "a") out.write(node["text"]) out.write("\n\n") out.close() os.chdir("..") # go one level up in the directory tree
I now see following in the Yogi Berra's quotes file:
You can observe a lot just by watching. Life is a learning experience, only if you learn. You got to be careful if you don't know where you're going, because you might not get there.
TRAVERSING DIRECTORIES
following program will walk through the directory structure we have just created and recursively delete all files that match *txt pattern
import os import fnmatch start_dir = "quotes_output" for dirpath, dirs, files in os.walk(start_dir): for single_file in files: if fnmatch.fnmatch(single_file, "*txt"): print("Deleting ", single_file) os.remove(os.path.join(dirpath, single_file))
Following program will copy all quote.txt files into destination.txt. File clashes will be handled based on OS overwriting policies
On my mac, every copy will overwrite the destination.txt and we will end up with only one file at the end
If target file does not exist it will be created
If target matches an existing directory name, then the files will be copied to that directory
in the following example, copy_to was existing directory and the files were copied into dest directory
import os import fnmatch import shutil start_dir = "quotes_output" copy_to = "dest" for dirpath, dirs, files in os.walk(start_dir): for single_file in files: if fnmatch.fnmatch(single_file, "*txt"): print("Copying ", single_file) shutil.copy(os.path.join(dirpath, single_file), copy_to)
using shutil.move(os.path.join(dirpath, single_file), to_dir) will move the files to the "destination" directory
If the file already exists in the new directory, the clash will be handled based on OS overwriting policies. On my mac, it errored out
shutil.move() can also be used to move a directory inside another directory
>>> import shutil
>>> shutil.move("fortune1", "destination")
PICKLING
pickle library in Python allows you to write and read (serialize and de-serialize) objects into binary files. Not everything is picklable, the list of what can be pickled can be found here
import pickle mylist = ["a", "b", "c"] with open("my.pickle", "wb") as pickle_file: pickle.dump(mylist, pickle_file)
this created my.pickle file and this is what the file looks like inside:
8003 5d71 0028 5801 0000 0061 7101 5801 0000 0062 7102 5801 0000 0063 7103 652e
This code snippet will load the mylist back from the binary file:
import pickle with open("my.pickle", "br") as pickle_file: my_list = pickle.load( pickle_file) print(my_list)
Following program reads the quotes from the JSON file and pickles them into binary
import pickle import json with open("quotes.json", 'r') as quotes_file: data = json.load(quotes_file) with open("quotes.pickle", "bw") as pickle_file: pickle.dump(data, pickle_file)
and then read it back:
import pickle import pprint with open("quotes.pickle", "br") as pickle_file: my_data = pickle.load(pickle_file) pprint.pprint(my_data)
SHELVING
Shelving lets you store data in files in a dictionary-like structure
the keys must be strings, the value can be any pickleable object (see reference above)
the keys must be strings, the value can be any pickleable object (see reference above)
>>> import shelve >>> sh = shelve.open("my_items") >>> sh["list"]=[1,2,3,4] >>> sh <shelve.DbfilenameShelf object at 0x7fb47eb02190> >>> sh["list"] [1, 2, 3, 4]
The true (binary) write will only happen when you do sh.close()
>>> sh.close()
Once you close the shelf, you cannot use it, you need to re-open it
>>> sh["list"] Traceback (most recent call last): File "/Users/gulanurmatova/opt/anaconda3/lib/python3.7/shelve.py", line 111, in __getitem__ value = self.cache[key] KeyError: 'list' During handling of the above exception, another exception occurred: Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/Users/gulanurmatova/opt/anaconda3/lib/python3.7/shelve.py", line 113, in __getitem__ f = BytesIO(self.dict[key.encode(self.keyencoding)]) File "/Users/gulanurmatova/opt/anaconda3/lib/python3.7/shelve.py", line 70, in closed raise ValueError('invalid operation on closed shelf') ValueError: invalid operation on closed shelf >>> sh = shelve.open("my_items") >>> sh["list"] [1, 2, 3, 4]
REGULAR EXPRESSIONS (REGEX, RE)
- Plain characters match themselves try here and here
- Dot (.) matches any one character, but if you want to match the dot, use \. try here
- Question Mark(?) denotes optional and if you need to match the question mark itself, use \? try here
- [abc] will match one of a, b or c characters. try here
- [^abc] will match any one character, except for a, b or c try here
- [A-Z] matches any one character A through Z (caps), [A-z] matches any alphabet character upper or lower case, [0-9] matches any one digit and you can combine those, like [a-z0-9] try here
- a{3} will match the a character exactly three times, a{1,3} will match the a character no more than 3 times, but no less than once try here
- a+ matches one or more a's, [abc]+ one or more of any a, b, or c character and .* zero or more of any character try here
- white space characters \t - tab, \n - new line, \r carriage return, \s covers all space characters try here
- ^ - matches beginning of the line and $ matches end of the line try here
- () captures groups try here
- (()) captures subgroups try here and here
- a|b will match a OR b try here
- \d represents digit, \D any non-digit
- \w represents alphanumeric characters, equivalent to [A-Za-z0-9_] , \W any non-alphanumeric character
- \S represents a non-space character
>>> import re >>> regexp = re.compile("hello") >>> line = "hello, how are you? it would be good to see you again" >>> regexp.search(line) <re.Match object; span=(0, 5), match='hello'>
Following code lets user enter a text and a regular expression to search in the given text
import re while True: user_match = input("Enter match text:") user_regexp = input("Enter regular expression (enter 'quit' to quit):") if(user_regexp == 'quit'): break regexp = re.compile(user_regexp) x = regexp.search(user_match) if(x): print("Match found at position {}".format(x.start())) else: print("Match is not found")
Enter match text:Hello World! Enter regular expression (enter 'quit' to quit):\s Match found at 5 Enter match text:Hello World! Enter regular expression (enter 'quit' to quit):\w Match found at 0 Enter match text:Hello World! Enter regular expression (enter 'quit' to quit):\d Match is not found
re.split() function returns a list where the string has been split at each match
import re txt = "The rain in Spain" x = re.split("\s", txt) print(x)
['The', 'rain', 'in', 'Spain']
re.sub() function replaces the matches with the text of your choice:
import re txt = "The rain in Spain" x = re.sub("\s", "9", txt) print(x)
The9rain9in9Spain
RAW STRINGS
Raw strings are often used for compiling regular expressions and is a way of asking Python not to process the string for special characters, this is done due to Python string escape may be misinterpreted for what you were trying to achieve with the RE
Raw string is prepended with r before the string literal, ex: my_string=r'hello'
Raw string is prepended with r before the string literal, ex: my_string=r'hello'
>>> s = "\t" >>> s '\t' >>> r=r"\t" >>> r '\\t'
Here is an example of how things could go wrong
>>> import re >>> regexp1 = re.compile("\\test") >>> print(regexp1.search("\\test")) None >>> regexp2 = re.compile(r"\\test") >>> print(regexp2.search("\\test")) <re.Match object; span=(0, 5), match='\\test'>
EXTRACTING MATCHED TEXT
import re regexp = re.compile(r"^\(?\d{0,3}\)?-?\d{3}-\d{4}$") if regexp.search("(203)444-3453"): print("(203)444-3453 matches") if regexp.search("444-3453"): print("444-3453 matches") if regexp.search("203-444-3453"): print("203-444-3453 matches") #this doesn't match because of the ^ if regexp.search("abc444-3453"): print("abc444-3453 matches")
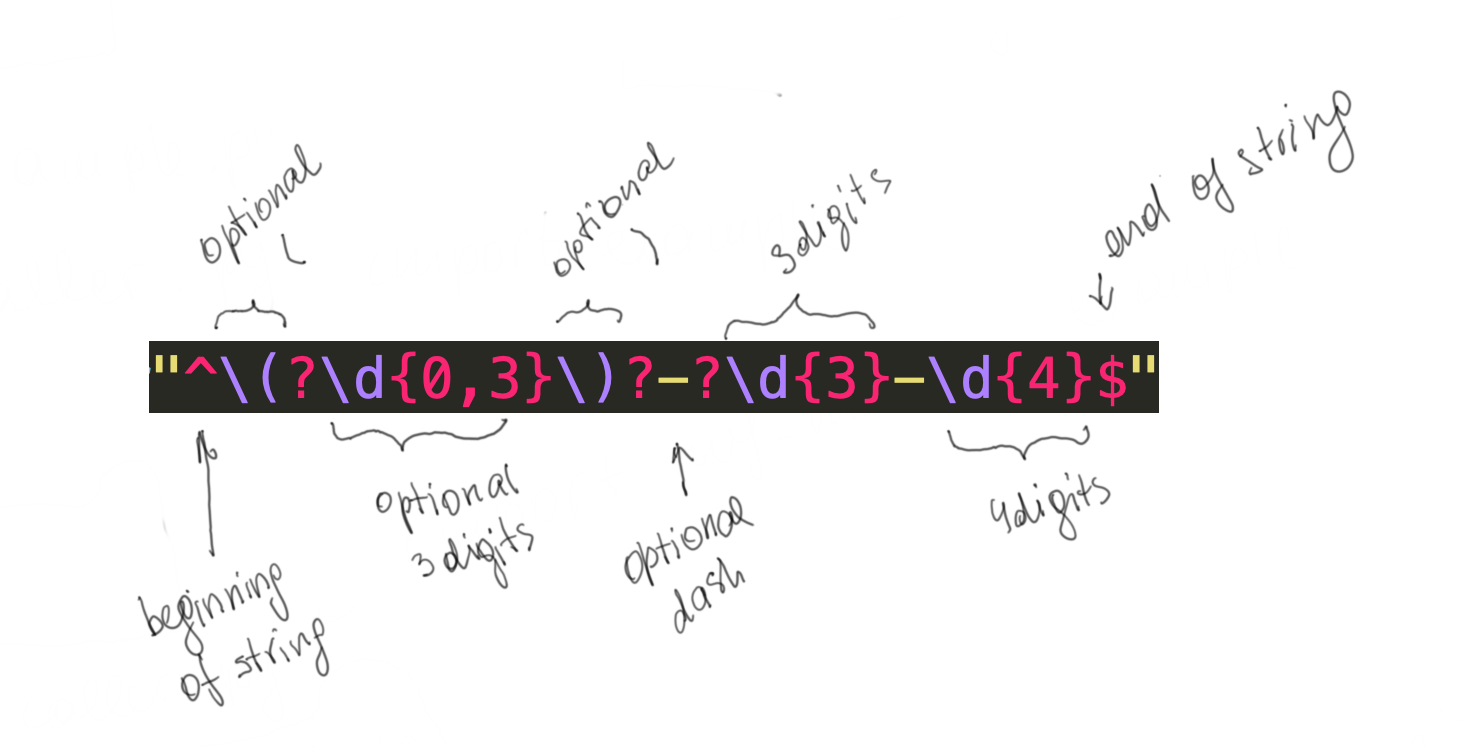
$ python regexp_matcher.py (203)444-3453 matches 444-3453 matches 203-444-3453 matches
Let's extract just the area code now
import re regexp = re.compile(r"^\(?(?P<area>\d{0,3})\)?-?\d{3}-\d{4}$") result = regexp.search("(203)444-3453") print("Area Code:{}".format(result.group("area"))) result = regexp.search("605-444-3453") print("Area Code:{}".format(result.group("area")))
$ python regexp_matcher.py Area Code:203 Area Code:605
And area code and number:
import re regexp = re.compile(r"^\(?(?P<area>\d{0,3})\)?-?(?P<number>\d{3}-\d{4})$") result = regexp.search("(203)444-3453") print("Area Code:{}".format(result.group("area"))) print("Phone Number:{}".format(result.group("number"))) result = regexp.search("605-999-3453") print("Area Code:{}".format(result.group("area"))) print("Phone Number:{}".format(result.group("number")))
$ python regexp_matcher.py Area Code:203 Phone Number:444-3453 Area Code:605 Phone Number:999-3453
Let's write a program that parses a log data and extracts the certain data, the file format is:
Thu Sep 16 2014 00:15:06 mailsv1 sshd[4351]: Failed password for invalid user guest from 86.212.199.60 port 3771 ssh2
Thu Sep 16 2014 00:15:06 mailsv1 sshd[2716]: Failed password for invalid user postgres from 86.212.199.60 port 4093 ssh2
Thu Sep 16 2014 00:15:06 mailsv1 sshd[2596]: Failed password for invalid user whois from 86.212.199.60 port 3311 ssh2
Thu Sep 16 2014 00:15:06 mailsv1 sshd[24947]: pam_unix(sshd:session): session opened for user djohnson by (uid=0)
Thu Sep 16 2014 00:15:06 mailsv1 sshd[3006]: Failed password for invalid user info from 86.212.199.60 port 4078 ssh2
Thu Sep 16 2014 00:15:06 mailsv1 sshd[5298]: Failed password for invalid user postgres from 86.212.199.60 port 1265 ssh2
Parse out and print IP address:
| log1.log |

import re f = open("log1.log") regexp = re.compile(r"(?P<ip>(\d{0,3}\.){3}\d{0,3})") while True: s = f.readline() if not s: break result = regexp.search(s) if result: ip = result.group("ip") print(ip) f.close()
... 188.138.40.166 10.2.10.163 188.138.40.166 87.194.216.51 87.194.216.51 87.194.216.51 10.2.10.163 ...
IP and Port:
import re f = open("log1.log") regexp = re.compile(r"(?P<ip>(\d{0,3}\.){3}\d{0,3})\sport\s(?P<port>\d{4})") while True: s = f.readline() if not s: break result = regexp.search(s) if result: ip = result.group("ip") port = result.group("port") print(ip+":"+port) f.close()
... 10.3.10.46:8419 50.23.124.50:1848 50.23.124.50:2479 50.23.124.50:3144 50.23.124.50:2694 50.23.124.50:4889 ...
re.findall can also be used to extract matches
import re f = open("log1.log") regexp = re.compile(r"(?P<user>\w+)\sfrom\s(?P<ip>(\d{0,3}\.){3}\d{0,3})\sport\s(?P<port>\d{4})") while True: s = f.readline() if not s: break for (letters) in re.findall(regexp, s): print(letters) f.close()
... ('games', '50.23.124.50', '124.', '2983') ('inet', '50.23.124.50', '124.', '3715') ('admin', '50.23.124.50', '124.', '1283') ('mail', '50.23.124.50', '124.', '2384') ('djohnson', '10.3.10.46', '10.', '8419') ('elena_andubasquet', '50.23.124.50', '124.', '1848') ...
HOMEWORK
Program 1
Very frequently there is a need to monitor a presence of a file in some directory, this maybe needed for:
write a program that will take a command line argument of full path and prints True if the file/directory at the provided location is present and False if it doesn't
Change program such that it runs indefinitely, monitoring a file/directory at a certain location and if the file disappears, then the program should print "Alert"
Program 2
Modify the quote generator program (on this page) such that if there are multiple quotes for the given author, instead of writing them out into the same file, the program instead creates a new file for each quote, hence if you have 3 quotes for an author, you would have 3 files in that author's folder, named quote_1.txt, quote_2.txt, quote_3.txt. If the author has only 1 quote, then file can be named wither quote.txt or quote_1.txt
Program 3
Prompt user to enter a start path and file name, search recursively for the given file name starting at the given path, when file is found, display the full path to the file.
Very frequently there is a need to monitor a presence of a file in some directory, this maybe needed for:
- Automated deployment jobs - every time a new bundle is uploaded, deploy it
- Synch processes - there are multiple clustered servers, and they need to have same files on them
- Error file - if file is ever present, then there is an error - send an email
write a program that will take a command line argument of full path and prints True if the file/directory at the provided location is present and False if it doesn't
Change program such that it runs indefinitely, monitoring a file/directory at a certain location and if the file disappears, then the program should print "Alert"
Program 2
Modify the quote generator program (on this page) such that if there are multiple quotes for the given author, instead of writing them out into the same file, the program instead creates a new file for each quote, hence if you have 3 quotes for an author, you would have 3 files in that author's folder, named quote_1.txt, quote_2.txt, quote_3.txt. If the author has only 1 quote, then file can be named wither quote.txt or quote_1.txt
Program 3
Prompt user to enter a start path and file name, search recursively for the given file name starting at the given path, when file is found, display the full path to the file.
Program 4:
Use decorator function you created for the previous homework and estimate how much operation on a dictionary is faster(or slower) than operation on a shelve